目录
- 前言
- 1. 查看optimizer trace配置
- 2. 开启optimizer trace
- 3. 线上问题复现
- 3. 使用optimizer trace
前言
MySQL优化器可以生成Explain执行计划,我们可以通过执行计划查看是否使用了索引,使用了哪种索引?
但是到底为什么会使用这个索引,我们却无从得知。
好在MySQL提供了一个好用的分析工具 — optimizer trace(优化器追踪),可以帮助我们查看优化器生成执行计划的整个过程,以及做出的各种决策,包括访问表的方法、各种开销计算、各种转换等。
1. 查看optimizer trace配置
show variables like '%optimizer_trace%';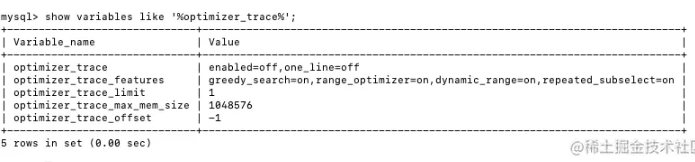
输出参数详解:
optimizer_trace 主配置,enabled的on表示开启,off表示关闭,one_line表示是否展示成一行
optimizer_trace_features 表示优化器的可选特性,包括贪心搜索、范围优化等
optimizer_trace_limit 表示优化器追踪最大显示数目,默认是1条
optimizer_trace_max_mem_size 表示优化器追踪占用的最大容量
optimizer_trace_offset 表示显示的第一个优化器追踪的偏移量
2. 开启optimizer trace
optimizer trace默认是关闭,我们可以使用命令手动开启:
SET optimizer_trace="enabled=on";
3. 线上问题复现
先造点数据备用,创建一张用户表:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL COMMENT '姓名',
`gender` tinyint NOT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_gender_name` (`gender`,`name`)
) ENGINE=InnoDB COMMENT='用户表';
创建了两个索引,分别是(name)和(gender,name)。
执行一条SQL,看到底用到了哪个索引:
select * from user where gender=0 and name='一灯';
跟期望的一致,优先使用了(gender,name)的联合索引,因为where条件中刚好有gender和name两个字段。
我们把这条SQL传参换一下试试:
select * from user where gender=0 and name='张三';
这次竟然用了(name)上面的索引,同一条SQL因为传参不同,而使用了不同的索引。
到这里,使用现有工具,我们已经无法排查分析,MySQL优化器为什么使用了(name)上的索引,而没有使用(gender,name)上的联合索引。
只能请今天的主角 —optimizer trace(优化器追踪)出场了。
3. 使用optimizer trace
使用optimizer trace查看优化器的选择过程:
SELECT * FROM information_schema.OPTIMIZER_TRACE;
输出结果共有4列:
QUERY 表示我们执行的查询语句
TRACE 优化器生成执行计划的过程(重点关注)
MISSING_BYTES_BEYOND_MAX_MEM_SIZE 优化过程其余的信息会被显示在这一列
INSUFFICIENT_PRIVILEGES 表示是否有权限查看优化过程,0是,1否
接下来我们看一下TRACE列的内容,里面的数据很多,我们重点分析一下range_scan_alternatives结果列,这个结果列展示了索引选择的过程。
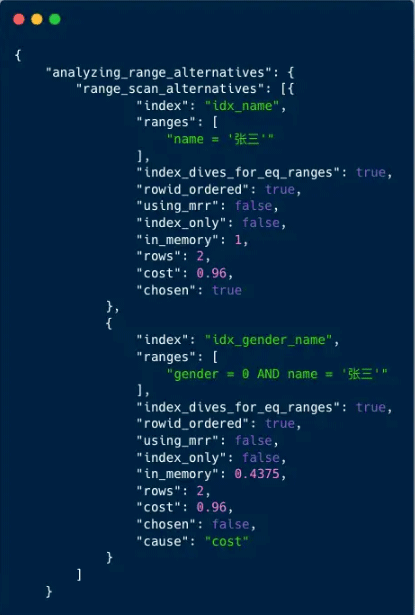
输出结果字段含义:
- index 索引名称
- ranges 查询范围
- index_dives_for_eq_ranges 是否用到索引潜水的优化逻辑
- rowid_ordered 是否按主键排序
- using_mrr 是否使用mrr
- index_only 是否使用了覆盖索引
- in_memory 使用内存大小
- rows 预估扫描行数
- cost 预估成本大小,值越小越好
- chosen 是否被选择
- cause 没有被选择的原因,cost表示成本过高
从输出结果中,可以看到优化器最终选择了使用(name)索引,而(gender,name)索引因为成本过高没有被使用。
再也不用担心找不到MySQL用错索引的原因,赶紧用起来吧!
到此这篇关于MySQL查询性能优化武器之链路追踪的文章就介绍到这了,更多相关MySQL链路追踪内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!